Large deviations

What is the probability that a random geometric graph in a sampling window has atypically few or atypically many edges or triangles? What are the mechanisms leading to such rare events? These questions illustrate the core problems of large deviations in geometric probability.
Condensation
For combinatorially defined random graphs, developing appropriate tools to understand the precise nature of large deviations has been the starting point for a vibrant research direction. In the geometric setting, process-level large deviation theory for the Poisson point process explains large deviations in many models satisfying stabilization and exponential moment conditions. However, for fundamental examples such as the edge count in random geometric graphs, these moment conditions fail and the process-level theory breaks down. In analogy with sums of heavy-tailed random variables, the resulting large-deviation behavior is governed by condensation phenomena, where only a small number of geometric structures dominate the deviation.
A concrete manifestation of condensation arises in upper large deviations of power-weighted distances in the $k$-nearest neighbor graph. In a paper with D. Willhalm, we show that if the power exceeds the spatial dimension, then only finitely many edges contribute substantially to an atypically large total power-weighted edge length. In a follow-up work, we study lower tails of Betti numbers across sparse, thermodynamic, and dense regimes. In a paper with K. Nam, we analyze concentration properties of the isoperimetric profile and identify multiple phase transitions.
Related condensation mechanisms also appear in geometric models beyond Euclidean random geometric graphs. In a paper with T. Kang and T. Owada, we establish large deviation principles for the volume of $k$-nearest neighbor balls and show how atypical geometric configurations drive rare events. In subsequent work on hyperbolic geometry, in a paper with M. Otto, T. Owada and C. Thäle, we analyze large deviations for hyperbolic $k$-nearest neighbor balls, revealing geometric mechanisms that differ substantially from the Euclidean setting.
Large deviations for geometric functionals
In a paper with B. Jahnel and A. Tóbiás, we show how sprinkling-based regularization makes it possible to derive lower large deviations for a broad class of geometric functionals. These include clique counts in random geometric graphs, intrinsic volumes of Poisson–Voronoi cells, and power-weighted edge lengths in random geometric, $k$-nearest neighbor, and relative neighborhood graphs.
In a follow-up work with M. Petráková, we extend these techniques to canonical Gibbs measures, thereby connecting large deviations for geometric observables with equilibrium statistical mechanics.
Complementary to these results, we investigate sharp asymptotic bounds for geometric observables across different scaling regimes. In a companion paper with the same coauthor, we establish matching lower large deviations, thereby providing a comprehensive description of rare-event behavior across regimes.
Beyond graph-based interactions, many applications require modeling higher-order relations. In a paper with T. Owada, we establish a large deviation principle for the point process associated with $k$-element connected components in the sparse regime. As examples of topological observables, we consider persistent Betti numbers of geometric complexes and the number of Morse critical points of the min-type distance function.
Large deviations and Monte Carlo simulations
While large deviation principles describe asymptotic regimes, their insights are also valuable for finite observation windows, particularly when constructing efficient estimators for rare-event probabilities. In a paper with S.B. Moka, T. Taimre and D.P. Kroese, we develop conditional Monte Carlo algorithms for estimating rare-event probabilities in random geometric graphs. Building on insights from large deviation theory, we demonstrate that importance sampling based on Gibbsian point processes can substantially reduce estimation variance. In a follow-up work, we extend these ideas and derive logarithmically efficient importance sampling schemes.
Large deviations for artificial neural networks
As artificial intelligence is increasingly deployed in security-critical applications, it becomes essential to understand the behavior of neural networks under rare events. In a paper with D. Willhalm, we study large deviations for one-hidden-layer neural networks trained via stochastic gradient descent with quadratic loss. We derive quenched and annealed large deviation principles for the empirical weight evolution when both the number of neurons and the number of training iterations tend to infinity, treating the weight dynamics as an interacting particle system.
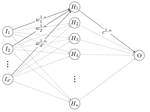
This line of research is complemented by further work on large deviations for neural networks from a statistical mechanics perspective. In a paper with L. Andreis and F. Bassetti, we study large deviations of one-hidden-layer neural networks at initialization, identifying the role of rare weight configurations in shaping atypical network outputs.
Large deviations for quantum systems
In joint work with P. Jung and S. Jansen, we derive a level-3 large deviation principle for a Gibbsian point process arising in a quasi-one-dimensional quantum jellium model, building on the Feynman–Kac representation of quantum statistics (code).
Large deviations for spatial preferential attachment
Spatial preferential attachment networks provide a natural framework for studying the interplay between geometry and reinforcement. In a paper with C. Mönch, we analyze shortest-path distances in such networks and establish a large deviation principle for the neighborhood structure (code).
Christian Hirsch
Associate Professor for Data Science and Statistics
Publications
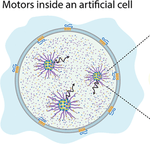
Modelling active particle motion from fluorescence correlation spectroscopy data
Efficient Rare-Event Simulation for Random Geometric Graphs via Importance Sampling
The contact process on a bipartite spatial network
Central limit theorem for linear eigenvalue statistics of random geometric graphs
Large deviations of one-hidden-layer neural networks
Actin Polymerizing Motors to Assist Cytoskeleton-like Networks Formation in Artificial Cells
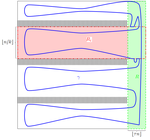
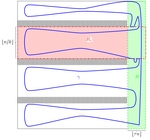
Large deviations for the isoperimetric constant in 2D percolation
Poisson approximation of fixed-degree nodes in weighted random connection models
Large Deviation Analysis for Canonical Gibbs Measures
On the topology of higher-order age-dependent random connection models
Lower large deviations for geometric functionals in sparse, critical and dense regimes
Upper large deviations for power-weighted edge lengths in spatial random networks
Asymptotic properties of one-layer artificial neural networks with sparse connectivity

Large deviations in the quantum quasi-1D jellium

Rare Events in Random Geometric Graphs

Lower large deviations for geometric functionals

Distances and large deviations in the spatial preferential attachment model

Large deviations for the capacity in dynamic spatial relay networks
Space-time large deviations in capacity-constrained relay networks